The Shangtang Technology Algorithm Platform team, in collaboration with the Peking University Energy Efficiency Lab, introduced an FPGA-based fast Winograd algorithm that significantly reduces computational complexity and enhances the performance of Convolutional Neural Networks (CNN) on FPGAs. This innovation was first demonstrated in 2016 through experiments using the best CNN architecture at the time, achieving optimal performance and energy efficiency under FPGA acceleration.
Summary
In recent years, Convolutional Neural Networks (CNNs) have become a cornerstone in computer vision tasks such as image classification, object detection, and semantic segmentation. With their high performance, low power consumption, and reconfigurability, FPGAs have emerged as powerful hardware accelerators for CNNs. However, traditional convolution algorithms used in previous FPGA solutions often faced limitations due to constraints like the number of DSPs available on the device. To address these challenges, this paper presents a fast Winograd algorithm that dramatically reduces algorithmic complexity and improves CNN performance on FPGAs.
We proposed a novel architecture to implement the Winograd algorithm efficiently on FPGAs. Our design employs a line buffer structure to enable efficient reuse of feature map data across different tiles. Additionally, we optimized the Winograd Processing Element (PE) engine by parallelizing multiple PEs to boost throughput. A complex design space exists when mapping the algorithm onto FPGAs, so we developed an analytical model to predict resource usage and infer performance. This model guided our rapid exploration of design options, leading to an optimized configuration. Using current state-of-the-art CNN models, our experiments showed that the solution achieves top performance and energy efficiency on FPGAs. On the Xilinx ZCU102 platform, we achieved impressive results: a convolutional average processing speed of 1006.4 GOP/s, an overall AlexNet processing speed of 854.6 GOP/s, a convolutional average speed of 3044.7 GOP/s, and a full VGG16 processing speed of 2940.7 GOP/s.
Introduction
Deep Convolutional Neural Networks (CNNs) have delivered remarkable performance in various computer vision tasks, including image classification, object detection, and semantic segmentation [1, 2]. However, the high accuracy of CNNs comes at the cost of significant computational complexity, as they require evaluating all regions in the feature maps [3, 4]. To address this challenge, researchers have turned to hardware accelerators such as GPUs, FPGAs, and ASICs to speed up CNN computations [5–17]. Among these, FPGAs stand out due to their high performance, low power consumption, and reconfigurable nature. Moreover, the use of High-Level Synthesis (HLS) tools like C or C++ has significantly lowered the programming barrier for FPGAs, boosting development productivity [18–20].
CNNs typically consist of multiple layers, where the output of one layer serves as the input for the next. Previous studies have shown that the majority of computation in modern CNNs is dominated by convolutional layers [6, 7]. Traditional convolution algorithms calculate each element in the output feature map through a multi-step multiply-accumulate process. While earlier FPGA-based solutions using conventional convolution algorithms have shown promise [5–9, 11], more efficient algorithms could lead to better performance. This paper explores how the Winograd algorithm can drastically reduce computational complexity and improve CNN performance on FPGAs. By leveraging structural similarities between elements in the output feature map, the Winograd algorithm minimizes the number of multiplications required, thus reducing the overall algorithm complexity. Research has shown that the fast Winograd algorithm is particularly effective for CNNs with small filters [16].
Notably, the current trend in CNN design favors deep architectures with small filters. For instance, AlexNet uses 3×3 and 5×5 filters in most of its convolutional layers [3], while VGG16 relies exclusively on 3×3 filters [22]. This makes the Winograd algorithm an ideal fit for optimizing CNN performance on FPGAs. However, implementing the Winograd algorithm on FPGAs still poses several challenges. First, the design must balance memory bandwidth requirements with computational throughput. Second, the mapping of the Winograd algorithm to FPGAs involves a large design space, making it difficult to determine which configurations will yield optimal performance.
To tackle these issues, this paper introduces a row buffer structure to cache feature maps for the Winograd algorithm, enabling efficient data reuse across different tiles. The Winograd algorithm involves a combination of general matrix multiplication (GEMM) and element-wise matrix multiplication (EWMM). Based on this, we designed an efficient Winograd PE and implemented parallel processing of multiple PEs. Finally, we developed analytical models to estimate resource usage and predict performance, allowing us to explore the design space and identify optimal parameters.
Contributions
This paper makes three key contributions:
1. Proposes an architecture that efficiently implements CNNs using the Winograd algorithm on FPGAs. The architecture incorporates a row buffer structure, GEMM and EWMM operations, and PE parallelization.
2. Develops analytical models for resource and performance prediction, which are used to guide design space exploration and optimize parameters.
3. Rigorously validates the proposed method using state-of-the-art CNN models, including AlexNet and VGG16.
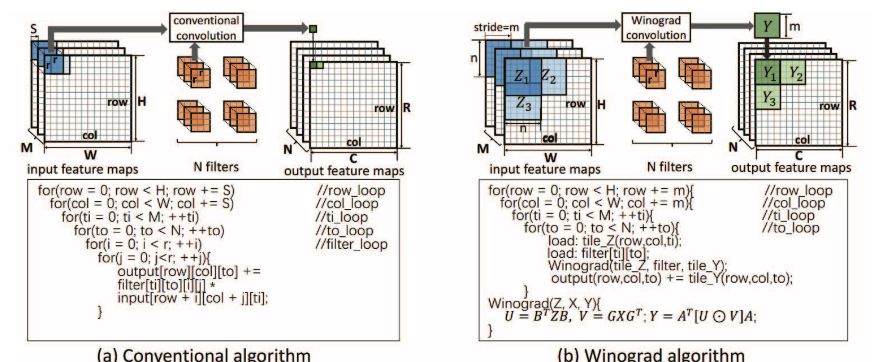
Figure 1: Comparison of traditional convolution algorithm and Winograd convolution algorithm. We assume that the stride S of the Winograd algorithm is 1.
Architecture Design
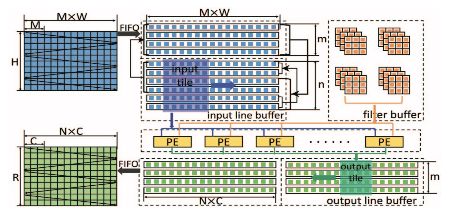
Figure 2: Architecture diagram
Figure 2 illustrates the convolutional layer architecture based on the Winograd algorithm on an FPGA. Researchers identified opportunities for data reuse in adjacent feature map tiles and implemented a line buffer accordingly. The input feature map (M) contains multiple channels, as shown in Figure 1. Each row of the line buffer stores the same row across all channels. The Winograd PE retrieves data from the line buffer. Specifically, given an n×n input tile, the Winograd PE generates an m×m output tile. To maximize throughput, researchers parallelized the processing of multiple channels. They also used double buffering to overlap data transfer and computation. All input data, such as input signatures and filters, are initially stored in external memory. Input and output feature maps are transferred to the FPGA via FIFO. However, as the network depth increases, filter sizes grow significantly, making it impractical to store all filters in on-chip memory. Therefore, the design divides input and output channels into multiple groups, with each group containing only part of the filter. Filters are loaded in batches as needed. For simplicity, the following discussion assumes a single group.
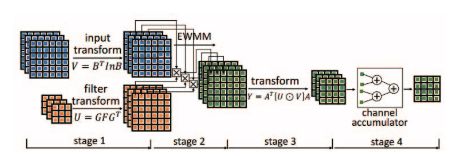
Figure 3: Winograd PE design icon
Automatic Tool Flow
The researchers designed an automated tool flow to map CNNs to FPGAs, as shown in Figure 5. The process includes a Design Space Exploration Engine (DSEE). The researchers used Caffe prototxt to describe the CNN structure [24]. FPGA configuration parameters include memory bandwidth, the number of DSPs, logic units, and on-chip memory capacity. The DSEE outputs the optimal solution {n, Tm, Tn}. In step 2, based on the optimal solution, the researchers developed a code generation engine (CGE) that automatically generates a Winograd convolution function. This function describes the entire accelerator structure, including row buffering, buffer management, and Winograd PE. The resulting implementation is an HLS-compatible C code. Instructions such as memory partitioning factors, loop unwinding factors Tn and Tm, and FIFO interface settings are embedded into the function. In step 3, the researchers used the Xilinx HLS tool to synthesize the code into a register transfer level (RTL). Finally, they used the Xilinx SDSoC toolchain to generate bitstreams.
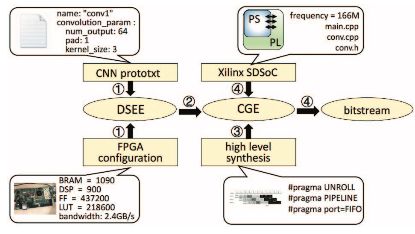
Figure 4: Automated tool flow
Experimental Evaluation

Table 1: Design parameters
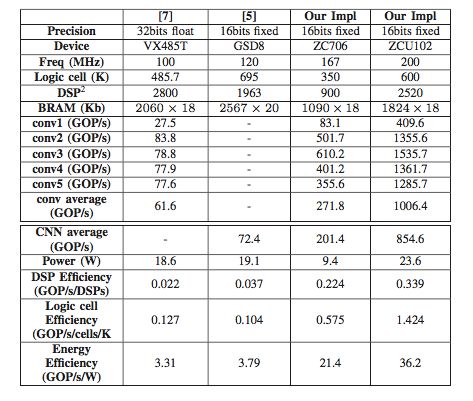
Table 2: Performance comparison of AlexNet
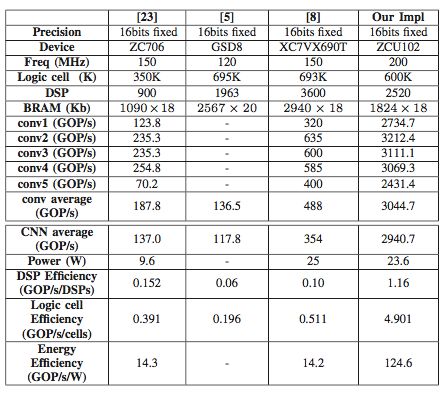
Table 3: Performance comparison of VGG
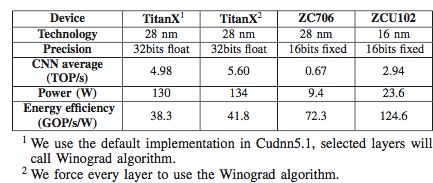
Table 4: GPU platform comparison
iPad Stylus Pen,Wireless Stylus for iPad,Bluetooth Stylus Pen for iPad,Stylus Pen for iPad,Drawing Stylus Pen for iPad
Shenzhen Ruidian Technology CO., Ltd , https://www.wisonen.com