The Shangtang Technology Algorithm Platform team, in collaboration with the Peking University Energy Efficiency Lab, introduced an FPGA-based fast Winograd algorithm that significantly reduces computational complexity and enhances CNN performance on FPGAs. This innovation was first demonstrated in 2016, where the researchers used the most advanced CNN architecture at the time and achieved optimal performance and energy efficiency under FPGA acceleration. The study laid a solid foundation for further research into efficient hardware acceleration of deep learning models.
Summary
In recent years, convolutional neural networks (CNNs) have become increasingly popular in computer vision tasks such as image classification, object detection, and semantic segmentation. FPGAs are gaining attention as effective hardware accelerators due to their high performance, low power consumption, and reconfigurable nature. However, traditional convolution algorithms often face limitations in terms of computational power, especially when constrained by the number of DSPs available on the FPGA. To address this, this paper presents a fast Winograd algorithm that dramatically reduces the algorithm's complexity and improves CNN performance on FPGAs.
Introduction
Deep Convolutional Neural Networks (CNNs) have shown remarkable performance across various computer vision tasks [1, 2]. However, their high accuracy comes at the cost of significant computational complexity, as they require evaluating all regions in the feature map [3, 4]. To tackle this challenge, researchers have turned to hardware accelerators like GPUs, FPGAs, and ASICs [5–17]. Among these, FPGAs stand out for their flexibility, low power consumption, and high performance. Additionally, High-Level Synthesis (HLS) tools for C/C++ have made FPGA programming more accessible and efficient [18–20].
CNNs typically consist of multiple layers, with each layer’s output serving as the input for the next. Research has shown that current optimal CNNs are largely dominated by convolutional layers [6, 7]. Traditional convolution algorithms calculate each element in the output feature map through a series of multiply-accumulate operations. While previous FPGA implementations using conventional methods have achieved initial success [5–9, 11], there is still room for improvement. This paper demonstrates how the Winograd algorithm can reduce computational complexity and enhance CNN performance on FPGAs by leveraging structural similarities in the output feature map elements.
Moreover, the trend in modern CNNs is toward deeper architectures with smaller filters. For example, AlexNet uses 3×3 and 5×5 filters in its convolutional layers (except the first), while VGG16 relies entirely on 3×3 filters [3, 22]. This makes the Winograd algorithm particularly suitable for accelerating such models. However, implementing it efficiently on FPGAs poses challenges, including minimizing memory bandwidth usage and optimizing the balance between computation and memory throughput. Additionally, the design space for mapping the Winograd algorithm on an FPGA is vast, making it difficult to determine which configurations will yield better performance.
To address these issues, this paper proposes a row buffer structure for caching feature maps, enabling data reuse across different tiles during convolution. It also introduces an efficient Winograd Processing Element (PE) and leverages parallelism to activate multiple PEs simultaneously. Furthermore, analytical models are developed to estimate resource usage and predict performance, allowing for rapid exploration of the design space and determination of optimal parameters.
Contributions of this paper include:
- An efficient architecture for implementing CNNs using the Winograd algorithm on FPGAs, incorporating row buffers, GEMM, EWMM, and PE parallelization.
- Development of analytical models for resource and performance prediction, guiding the design space exploration process.
- Rigorous validation of the proposed technique using state-of-the-art CNNs like AlexNet and VGG16.
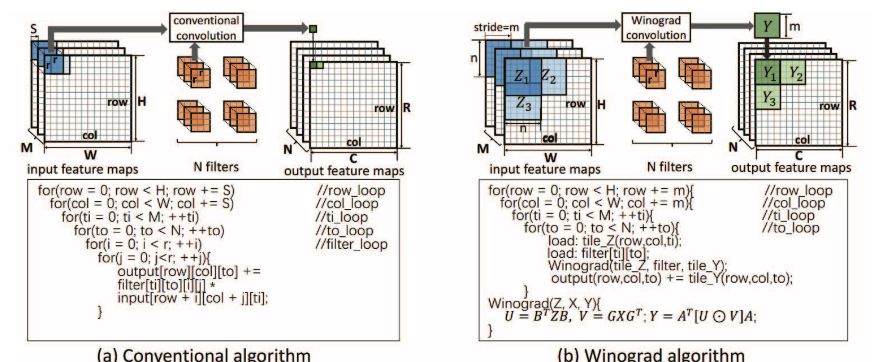
Figure 1: Comparison of traditional convolution algorithm and Winograd convolution algorithm. We assume that the stride S of the Winograd algorithm is 1.
Architecture Design
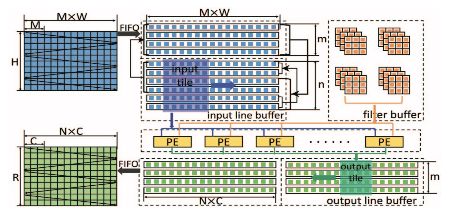
Figure 2: Architecture diagram
Figure 2 illustrates the convolutional layer architecture based on the Winograd algorithm on an FPGA. The researchers identified opportunities for data reuse across adjacent tiles in the feature maps. As a result, a line buffer structure was naturally implemented. The input feature map (M) consists of multiple channels, as shown in Figure 1. Each row of the line buffer stores the same row from all channels. The Winograd PE retrieves data from the line buffer. Specifically, given an n×n input tile, the Winograd PE generates an m×m output tile. The researchers enabled the PE array by parallelizing the processing of multiple channels. Finally, double buffering was used to overlap data migration and computation. All input data, such as input signatures and filters, are initially stored in external memory. Input and output feature maps are transferred to the FPGA via FIFO. However, as the depth of the network increases, the size of the filter also grows, making it impractical to load all filters into on-chip memory. In this design, the researchers divided the input and output channels into multiple groups. Each group contains only a portion of the filter, and the filter is loaded on a per-group basis. For simplicity, the following explanation assumes there is only one group.
3 Mm /8 Mm Nano Tip,Electronic Board Marker Pen,Touch Board Marker Pens,Infared Smart Board Marker
Shenzhen Ruidian Technology CO., Ltd , https://www.wisonen.com