At present, embedded multi-core processors have been widely used in the field of embedded devices, but the embedded system software development technology still stays in the traditional single-core mode, and does not give full play to the performance of multi-core processors. Program parallelization optimization has some applications on the PC platform, but it is still rare on the embedded platform. In addition, the embedded multi-core processor is very different from the PC platform multi-core processor, so it is not possible to directly parallelize the PC platform. The optimization method is applied to the embedded platform. In this paper, the parallelization optimization of task parallelism and cache optimization is studied respectively, and the method of parallel optimization of program on embedded multi-core processor is explored.
1 embedded multi-core processor structure
The structure of the embedded multi-core processor includes both Symmetric and Asymmetric. Isomorphism means that the structure of the internal core is the same. This structure is currently widely used in PC multi-core processors. Heterogeneous means that the structure of the internal core is different. This structure is often used in the embedded field. Universal embedded processor + DSP core. The embedded multi-core processor explored in this paper adopts a homogeneous structure to realize parallel execution of the same piece of code on different processors.
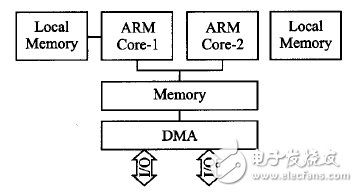
Figure 1 ARM SMP processor structure
In the current embedded field, the most widely used ARM processor, so the ARM dual-core processor OMAP4430 as the research object. The structure of the ARM Symmetric MulTI-Processing (SMP) is shown in Figure 1. According to the locality principle of the program, each processor has a private memory (Local Memory), and a common one is the L1Cache. However, multiple processors are involved in intercommunication problems, so L2 Cache is used in common ARM processors to solve this problem. Based on a symmetric multiprocessor architecture, all processors (usually a multiple of 2) are identical in hardware structure and are equally equal in terms of system resources used. More importantly, since all processors have the right to access the same memory space, in the shared memory area, any process or thread can run on any processor, which makes the parallelization of the program become may. 2 Parallel optimization on an embedded multi-core platform requires consideration of the following issues:
1 The performance of the parallelizer depends on the serialization part of the program, and the program performance does not increase as the number of parallel threads increases;
2 embedded multi-core processor is slower than PC processor, and the cache is smaller, which will cause a large amount of data to be continuously copied in memory and cache. Therefore, parallel operation is performed. Cache friendly should be considered in the process of optimization;
3 The number of parallel execution threads of a program should be less than or equal to the number of physical processors. Too many threads will cause processor resources to be preempted between threads, resulting in degraded performance.
2 OpenMP parallelization optimization
2.1 Introduction to 0penMP working principle
OpenMP is a cross-platform multi-threaded parallel programming interface based on shared memory mode. The main thread generates a series of child threads and maps the tasks to child threads for execution. These child threads execute in parallel, and the runtime environment allocates threads to different physical processors. By default, each thread executes the code for the parallel region independently. You can use work-sharingconstructs to divide tasks so that each thread executes the code for its allocated portion. In this way, task parallelism and data parallelism can be achieved using OpenMP.
Figure 2 Task Parallel Model
The task parallel mode creates a series of independent threads, each of which runs a task, and the threads are independent of each other, as shown in Figure 2. OpenMP uses the compiled primitives session direcTIve and task direcTIve to implement task assignment. Each thread can run different code regions independently, while supporting task nesting and recursion. Once a task is created, the task may execute on a thread that is free in the thread pool whose size is equal to the number of physical threads.
Data parallelism is data-level parallelism, and the data processed in the task is performed in parallel and in parallel, as shown in Figure 3. The for loop in C is best suited for data parallelism.
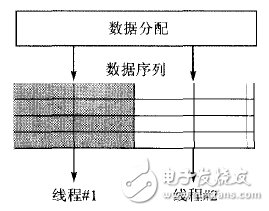
Figure 3 data parallel model
2.2 Principles of Fast Sorting Algorithm
The quick sort algorithm is a recursive divide and conquer algorithm. The most critical part of the algorithm is to determine the pivot data. Data smaller than the sentinel in the data sequence will be placed to the left of the sentinel element, and data larger than the sentinel in the sequence will be placed to the right of the sentinel element. When the data scan is completed, the left and right parts of the sentinel element are called recursively by calling the quick sort algorithm.
The recursive call of the algorithm involved in the quick sort algorithm generates a large number of tasks, and these tasks are independent of each other, which is very suitable for OpenMP's task parallel mode. In addition, for a fast sort search algorithm, the sentinel element has the data size of the left and right subintervals. The decisive role, considering the cache space of the embedded platform is small, it is necessary to optimize the sentinel element screening algorithm, try to make the divided left and right sub-intervals more balanced, and meet the requirements of load balancing.
2.3 Task Parallel Optimization
Through the analysis of the quick sort algorithm, fast sorting is a recursive calling algorithm. During the execution of the algorithm, a large number of repeated function calls are generated, and the execution of the functions is independent of each other. For a quick-sorting scan operation, the algorithm first determines the sentinel element and adjusts the data sequence once, and then recursively calls the left and right intervals of the sentinel element again.
As shown below, the task parallelization optimization is optimized for each scan of the left and right subintervals, and the operation of each subinterval is abstracted into one task, and the task parallelization is realized by the task parallelization primitive #pragma omp task in OpenMP. Execution, which enables fast parallelization of task parallelization optimization.


The size of the data in the task space depends on the sentinel element. Therefore, the algorithm selected by the algorithm should equalize the division of the data sequence. This paper uses the simple partition algorithm and the ternary median method (Median-of-Three Method). )carry out testing.
More embedded design materials, you can enter the ARM technology topic of the core technology of the Internet of Things, which is honored by electronic enthusiasts!

Lifepo4 Lithium Battery,26650 Battery,3.2V Lifepo4 Lithium-Ion Battery ,26650-3300Mah Battery
Henan Xintaihang Power Source Co.,Ltd , https://www.taihangbattery.com