Clustering analysis is a powerful technique used to group data points into clusters where objects within the same cluster are more similar to each other than to those in other clusters. This process is automatic, allowing the algorithm to discover hidden patterns and structures without prior knowledge of class labels. It plays a crucial role in unsupervised learning, where the goal is to uncover underlying relationships in unlabeled datasets.
Unlike supervised learning, which relies on labeled data for training, clustering operates on unstructured data, grouping samples based on their inherent similarity or distance. The core idea is to minimize internal dissimilarity while maximizing external differences between clusters. This approach is widely used in various fields such as market segmentation, image recognition, and anomaly detection.
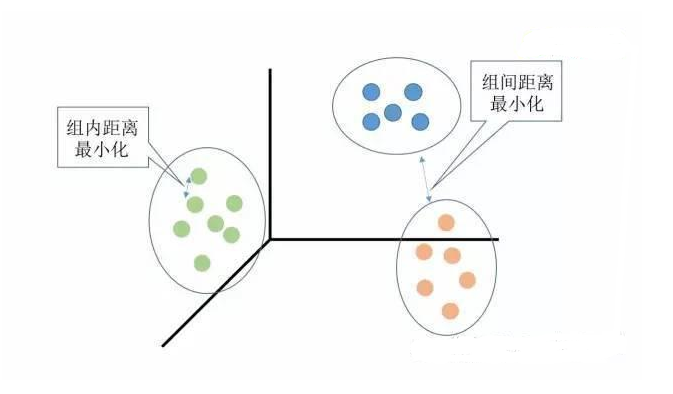
Some of the most commonly used clustering algorithms include K-Means, K-Medoids, Hierarchical Clustering, and Density-Based methods like DBSCAN. Each has its own strengths and weaknesses, making them suitable for different types of data and applications.
K-Means is one of the simplest and most widely used clustering techniques. It partitions the dataset into K clusters by minimizing the sum of squared distances between data points and their assigned cluster centers. While it's efficient for large datasets, it can be sensitive to outliers and initial centroid selection.
K-Medoids, also known as the K-Center Point method, improves upon K-Means by using actual data points (medoids) as cluster centers instead of means. This makes it more robust against noise and outliers, though it tends to be computationally more expensive.
Hierarchical Clustering builds a tree-like structure of clusters, either by merging smaller clusters (agglomerative) or splitting larger ones (divisive). It’s particularly useful for visualizing data relationships but may not scale well with very large datasets due to high computational complexity.
Density-Based Clustering, such as DBSCAN, identifies clusters based on the density of data points. It can detect clusters of arbitrary shapes and is effective at handling noisy data. Unlike K-Means, it doesn’t require the number of clusters to be specified beforehand.
In addition to these, there are also grid-based and model-based clustering methods that offer alternative approaches depending on the nature of the data and the problem at hand.
Understanding the principles and limitations of each algorithm is essential for selecting the right approach for a given task. Whether you're working with customer data, biological sequences, or image features, clustering provides a valuable tool for exploring and interpreting complex datasets.
110KV, 220KV Oil-resistant Heat-shrinkable Tubing
110KV, 220KV oil-resistant heat-shrinkable tubing
110KV, 220KV oil-resistant heat-shrinkable tubing,Heat-shrink tube,Heat shrinkable tubing,thermal contraction pipe,Shrink tube
Mianyang Dongyao New Material Co. , https://www.mydyxc.com