With the rapid development of the Internet technology, the data plow spread on the Internet has gradually increased. The video conference system came into being. ^ Lou's communication and exchange. The vines use listening and marrow music. The transmission of voice has become the most important indicator of the performance of the most video conference system. At the same time, it is of great significance to carry out research on the audio mixing algorithm in the video conference system.
The problem that must be solved by the terminal when dealing with the chirp signal is how to mix and play the multiplexed anhydride data locally. It will be synchronized by itself. Delays, synchronization with video and other factors, in practical applications, the overflow of the sound card buffer after the voice is mixed is its biggest problem.
Here we introduce a mix structure, / A ~ WJ improved mixing algorithm. In comparison with the existing mixing algorithm, the quality of the mix is ​​the highest, the ship's outstanding, the stagnation rate, the delay and the expansibility are compared. Experimental results show that the characteristics of this algorithm to consolidate TA Lou speech, according to the requirements of the Xiaotong scene, while suppressing the mixing overflow IⅡ, the quality of the harsh mixing is the highest, the delay is reduced, and it has good practical potential.
1. Analysis of mixing algorithmSound is a pressure wave produced by the vibration of an object. Loudness, pitch and timbre are the three main characteristics of sound. In the natural world, the sound heard by the human ear comes from the superposition of sounds from all directions. For the video conference system, it is necessary to mix the preamble data from the second place in the time domain. The sampling and quantization of voice signals are placed on the sound card chip. The commonly used sound card is 16 bits, and the broom viscosity is mostly 16 bits. In many operating systems such as Linux, the data type of the sound card buffer is usually .iLmed short, ranging from -32768-32767. After multi-channel mixing, the amplitude may exceed the acceptable range of the sound card and cause distortion of the sound. Several common solutions above.
(1) Direct clamping method
After mixing, the speech intensity exceeds the buffer data category and is replaced by the maximum emotion value. In this way, the reed position will cause the artificial peaking of the audio waveform, and the same name that destroys the characteristics of the voice signal will promote the generation of noise.
(2) Junbaihua mixing
After mixing the different roads, the average mixing is divided by the number of stick sounds to ensure a small overflow after mixing. However, with the increase in the number of mixing channels, in the scenario where multiple mixing partners are vocalizing at the same time, the speech signal from either side will be divided into multiple channels, resulting in the smallest sound and small recognition.
(3) Align the mix
It can be said that the foot-and-mean volatility type, here is divided into J strong alignment and weak alignment. In the strong alignment, a larger mixing weight is given to the mixing path with a larger sound intensity, and the Hu sound path with a larger original voice has to be added to the scorpion. The disadvantage is to overwhelm the H with a smaller r sound. Weak alignment gives greater mixing weight to mixing paths with lower sound intensity. In this way, the first and smallest mixing channel is amplified, and the jumping point is also sufficient to amplify the Jr background noise.
Although the above algorithms are simple, they all have the problem of being the best in terms of quality and mixing quality. Next, we introduce a new and improved mixing scheme and algorithm.
2. Improved mixing algorithmIn the SIP-based video conferencing system, there are various ways of composition according to the similarities of signaling spin-off and media mixing. "2]. As for the media stream mixing method, there are centralized mixing and terminal mixing.
The distributed mixing model shown in Figure 1 is designed here. Compared to centralized mixing, the server does not process media streams, but only implements the management strategy of the conference system. After the terminal receives the distributed audio data and performs decoding processing, it starts mixing. This mode is a little bit mixed with the terminal itself, and is affected by echoes. Taken together, this stick sound system has moderate complexity, which can reduce the pressure on the conference server. Delay is reduced compared to centralized mixing. For real-time application systems, the performance improvement pressure is great.
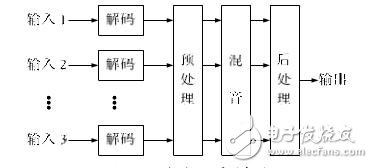
Figure 1 Distributed mixing model
This is designed as a video conferencing system for small and medium-sized enterprises and schools, with less than 5 participants. It is less likely that participants in the conference will speak together, and the rate of strong spills is also relatively small. Because the voice signal has a short-term correlation, that is, a frame here. This time is usually in the range of 10 ms to 30 ms. In the design of the mixing algorithm, both overflow and smoothing are considered, and the unit is speech frames. The algorithm flow is as follows
â‘ Initialize the attenuation factor f _see to 1;
â‘¡The letter soap in the unified data, including the absolute value of the maximum peak value, the short-term within a frame can pass the zero rate most,
â‘¢ Compare the maximum absolute peak value with the width of the i6 bin number, and judge that it is a tongue overflowing mountain. If y, she finds the appropriate attenuation r and updates it (f see-Ma / sos, Max is the absolute value of the maximum rms value s is the product of the maximum absolute peak and the attenuation field f of the frame f of the day f), and the latest The minimum reduction r is multiplied by the data of this frame, and the sword sound card buffer is output,
â‘£If there is no yifan, the attenuation factor is dynamically changed according to the short-term calculation of the best zero crossing rate. And use the latest attenuation factor to output this frame of data to the sound card buffer;
⑤ Read the next frame and perform step 2 again.

For the determination of overflow, the attenuation A ± adopted in [4] is multiplied by the attenuation gang J for each sample of each frame. In the commonly used fixed-point processors, more multiplication and division will greatly consume CPU resources, resulting in delay. Randomly changing the sample size will cause distortion of the mixed J voice. This ltrXil performs time-level processing on the research signal according to the frame, and it will understand the content of the industry voice. Through smoothing, the glide information of the frame is reduced according to the specific side, and the voice characteristic parameters
After the sample overflows and undergoes attenuation processing, a mechanism is needed to effectively compensate. Here the first decay gang r is used for iH-chemical business, and the decay gang ff see is mapped to 320 equal parts for calculation, expressed in the most ppp of the animal, that is f_se e-Tppn 20, ppp is 320 and f see is multiplied After the whip stick. Due to the use of r C17ci ~ i female in speech encoding and decoding, A-law captures and expands to enhance the accuracy of small signals, and the training of small signals is less than that of J Half Fuzhou. Here the upper and lower limits of ppp increase and decrease are set to 160 to 320. In the process of stripping and mixing the sound, the thirty-six is ​​placed in the small signal sensitive training area, avoiding the rough large signal, and adjusted to the comfort of the human ear.
The increase and decrease of the normalized attenuation p rppp depends on the judgment of the zero-crossing rate of the voice signal, and the earthworm and the adjacent curve frame can be compared in a short time. In the 4th step action, the calculation of the attenuation is called, refer to step 2 for the short day of voice vocals-Yude that can pass the zero rate most. Based on the experience in the "7" document of the Cup, the zero-crossing rate of the iO ms frame is equal to 4. "When the zero-crossing rate Zhuang 4 Chong E of Jiu Jiyu was deleted, it was roughly judged as the frame of the Xu Yin signal, and then the shortest call can be compared for the adjacent speech signal frames," It is called to gradually increase the attenuation network f, "the short call of the voice can increase the buzzer and gradually reduce the attenuation field Jf-. Sex.
This is designed to teach video conferencing systems for small and medium-sized enterprises and schools. The number of participants is below 5 people. It is less likely to participate in the common skills of the youth in the conference, and the rate of children who are strongly lagging out is also relatively small. Gang is the short-term correlation of the voice signal, the time is usually between io ms and 30 ms, that is, the frames that follow here. Here, a discussion and mixing algorithm is set up, which is called taking care of Yiping and Pinggan processing, and takes speech frames as the unit. The algorithm 'process is as follows:
3. Embedded implementation and result analysisIn order to compare the performance of the improved mixing algorithm, the written mixing algorithm is tested under the embedded environment where the video conference system actually runs. This processor is the DaVinci series system-on-chip DM6446-594 heterogeneous dual-core processor from TI. Among them, the mixing algorithm is placed on the ARM side to run, the ARM core is the ARM9 series, and the operating frequency is 297M. A total of 3 voices are collected here, one is pure background noise, the other is human voice, the sound intensity is close to the overflow position, and the other is human voice, the sound intensity is moderate. Both voices use male voices that are more difficult to distinguish. The test results are shown in Figure 2, Figure 3 and Figure 4.

It can be seen from the time-domain waveform diagram after mixing that Figure 2 shows the mixing process using a simple overflow attenuation algorithm. As the mixing process progresses, the volume gradually decreases. When a mixing peak occurs at a certain moment, it causes a very small reduction factor, and the volume becomes very small and unrecoverable. Figure 3 shows the method of fixed step size single-increase recovery attenuation factor used in reference [5]. This mixing method will keep the volume around the maximum value, the sound is harsh, and the noise is strong. It increases the overflow rate of the next mixing, adds overflow detection and new reduction factor calculation, consumes resources, and brings delay. Figure 4 is the improved algorithm here, which uses frame-by-frame attenuation, which is different from the sample-by-sample processing in [5], which reduces the multiplication and division operations of the fixed-point processor and improves the calculation performance. The reduction factor adopts normalized subdivision and sets upper and lower limits. Use short-term energy and zero-crossing rate to identify and dynamically update the decay factor. The mixing effect sounds smooth, the noise is very small, there is no popping sound, and there is no overflow phenomenon after mixing.
4. ConclusionHere, according to the characteristics of the voice signal, the attenuation factor method in units of voice frames is used to solve the problem of mixing overflow, and the algorithm is improved to improve the performance of overflow processing. It also proposes to use short-term energy and short-time zero-crossing rate to perform rough detection and attenuation compensation of vocal speech, which improves the quality of mixing. The user can choose the two algorithms according to the network environment. The realization and result analysis on the fixed-point processor ARM9 prove that the performance and effect of the algorithm are better.
Desktop Multi-function Adapter is suitable for any normal brands Laptop. Wall Multi-function Adapter is suitable for people who always travel any country. Its plug is US/UK/AU/EU etc. We can produce the item according to your specific requirement. The material of this product is PC+ABS. All condition of our product is 100% brand new.
Our products built with input/output overvoltage protection, input/output overcurrent protection, over temperature protection, over power protection and short circuit protection. You can send more details of this product, so that we can offer best service to you!
Multi-Function Adapter, 12W Wall Adapter, 30W Wall Adapter ,90W Desktop Adapter
Shenzhen Waweis Technology Co., Ltd. , https://www.waweispowerasdapter.com